只放了我出的几题的wp,其他见github
https://github.com/wm-team/WMCTF2020-WriteUp
bilibili直播的代码见gist。
by:小帽
XMAN_Happy_birthday!
打开题目看到文件名“daolnwod.zip”,看到文件结尾的4B 50不难想到将文件reverse后就能得到压缩包和flag
Performance_artist
简单的图像分类, 没想到大家都直接用眼睛做了。。

还好长度不是太长(压缩包里放个图片还做不做了emm)
按说把hint放的数据集放搜索引擎找一下就有很多带详解的代码了。为了降低难度,题目都是直接用的训练集,没有加噪音,也就是说不用考虑过拟合问题。(好像师傅们都是把图分出来直接匹配数据集去了= =)
代码见链接:
https://gist.github.com/yikongge/28aaf0aca7308bf3bc8a5a708ba14537
https://share.weiyun.com/3u6l23rJ
恢复好的文件链接: https://share.weiyun.com/pSxojEjM
哦 差点忘了 png图片有修改图片高度,压缩包进行了伪加密(比赛时有师傅发现图片显示的zip没有文件尾,没想到改png高度emm 个人感觉这两个知识点国内很常见 - -)
Music_game
念就好了。可能是数据集问题(wtcl),国人的发音识别的不太好,google翻译外放吧
(有看到有师傅用burp 应该也没问题
Music_game2
经过前面两个开胃菜的预热,前期准备工作应该完成了。
这道题说白了就是在音频里掺入些噪音,让后台的神经网络作出错误的判断。玩过上一题的师傅都知道,这个识别有点拉。
既然是掺杂,我比赛前突发奇想了一种“佛系解题”法
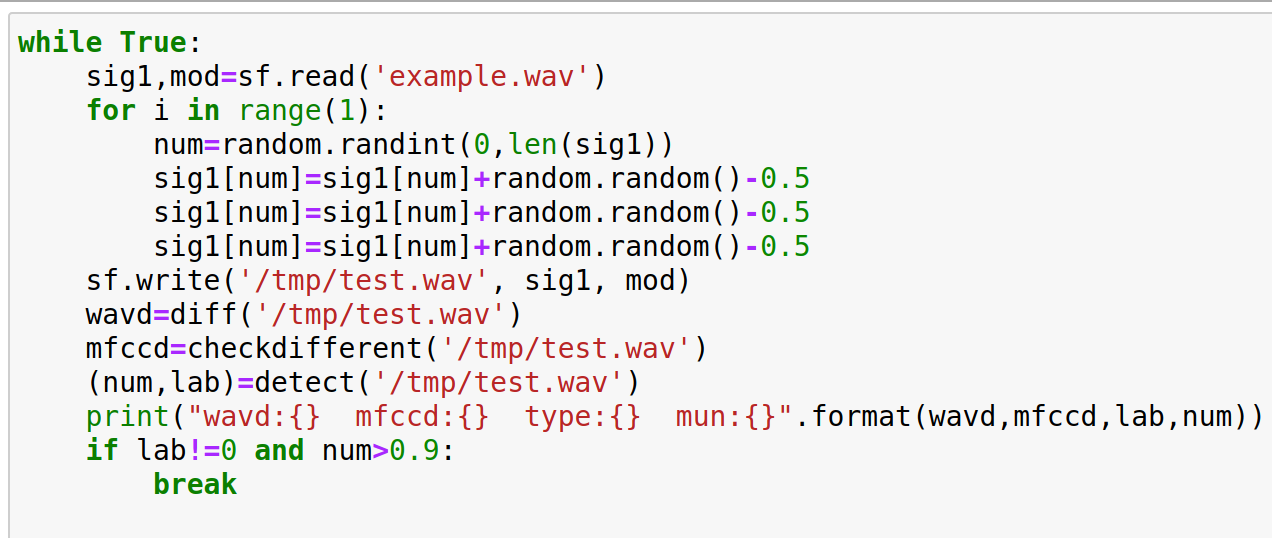
看到random了吧,就是随机往里写点随机的数据。这样居然真的可以,只是因为题目条件比较苛刻,向左很难成功欺骗。(比赛时有两个师傅提到向左不能伪造,听了他们伪造的音频,估计是用了相似的手段。)
下面是预期解,先放上两个参考文档,分别是介绍神经网络欺骗和mfcc转wav的python实现:
https://amyang.xyz/posts/Inverse-MFCC-to-WAV
(后来才知道 librosa已经有mfcc_to_audio方法了 )
主要思路是使用给出的模型识别example.wav,根据预测出的偏移反向传播调整音频。因为使用MFCC生成wav中间会有损耗,所以我的做法是利用wav生成的MFCC数据进行预测并不停地反向调整example.wav的MFCC原数据。这听起来有些绕口,具体见 脚本 ,(修改object_type_to_fake来修改欺骗的类型。)
https://gist.github.com/yikongge/40ed9bde7cc7616244afcfa9aed31e1e
https://share.weiyun.com/ilFwLKnc
(本题解法不唯一,这可能不是最优解,其他解法请自行检索
最后上传的问题不知道大家是不是做上一题时就有解决,前端自己加一个上传按钮就行了,或者用requests做…方法很多 外放估计行不通了。

